replace와 translate는 개발하다보면 아주 많이 쓴다.
replace나 translate 둘다 문자를 대체할때 사용을 하는데 예시를 보자.

이처럼 해당하는 문자를 모두 찾아 바꿔주는것이 replace이다.
그럼 translate는 뭘까?
translate('원래문자열','찾고싶은 문자들','찾고싶은 문자들의 순서와 바꾸고싶은 문자')
이렇게 쓸수있다.
어렵다.
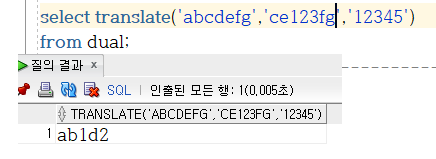
차근차근 보면 abcdefg라는 문자열에서 c, e, 1, 2, 3 문자를 하나하나 검색을한다.
처음은 c여서 봤는데 c가 포함되어있다. 그럼 이 c를 뭘로바꾸느냐? c 와 1 이 같은 위치니까 1로바꾼다.
그럼 ab1defg가 된다.
그다음 e는 2로 변경되어 ab1d2fg가 된다.
그다음 1과 2와 3은 포함된게 없으니 생략된다. 여기서 포함되는게 있다면 1,2,3 이 3,4,5로 바뀌게된다!
그리고 그다음 중요한 포인트가 나온다. f와 g는 분명히 본래문자열에 포함되어있다.
그런데 세번째 파라미터에 대응할수 있는 문자가 없다.
그럼 무조건 삭제된다!!! 그래서 결과는 ab1d2fg가 아니라 ab1d2이다!!!
이것을 이용하여 주민등록번호 검사로직을 만들어보았다.
replace대신 사용해보았는데 유용한것 같다! (replace 몇번 쓸것을 한번으로 처리할수 있었다!!)
--입력할 때 '-'를 입력해도 되고 스페이스를 쳐도됨
select decode(substr(translate(:personnum,'1234567890- ','1234567890'),13,1), --:마지막으로 끝번호와 비교하여 검증결과 출력
decode(length(11-mod(sum(substr(translate(:personnum,'1234567890- ','1234567890'),rownum,1)-- '-'와 공백이 있을 시 없애고 각자리에
*decode((rownum+1),10,2,11,3,12,4,13,5,rownum+1)),11)),--곱셈처리(decode로 10초과시 숫자변경)하고 sum 후, 11로나눈 나머지를 11에서 뺌
2, substr(11-mod(sum(substr(translate(:personnum,'1234567890- ','1234567890'),rownum,1)*decode((rownum+1),10,2,11,3,12,4,13,5,rownum+1)),11),2,1),
1, 11-mod(sum(substr(translate(:personnum,'1234567890- ','1234567890'),rownum,1)*decode((rownum+1),10,2,11,3,12,4,13,5,rownum+1)),11)),'검증완료','검증실패') result
from dual
connect by level<length(translate(:personnum,'1234567890- ','1234567890')); --11개
'Developer' 카테고리의 다른 글
| 고차함수란? (0) | 2020.07.31 |
|---|---|
| 인코딩이 무엇인가? 유니코드는 또 뭐야 (0) | 2020.07.31 |
| 아스키코드란 무엇인가? (0) | 2020.07.31 |
| 데이터베이스와 빅데이터의 차이점 (0) | 2020.07.31 |
| Decode와 Case의 차이점 (0) | 2020.07.29 |
